MySQL的日志主要有三种:binlog(二进制日志),redo log(重做日志),undo log(回滚日志)
- redo log 是物理日志,undo log 和 binlog 是逻辑日志
- binlog二进制日志是server层的无论MySQL用什么引擎,都会有的,主要是左主从复制,时间点恢复使用
- redo log重做日志是InnoDB存储引擎层的,用来保证事务安全
- undo log回滚日志保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
redo log(重做日志)
redo log 是物理日志,记载着每次在某个页上做了什么修改。写redo log也是需要写磁盘的,但它的好处就是顺序IO(我们都知道顺序IO比随机IO快非常多)。写入的速度很快
生命周期
- 事务开始之后,就开始产生 redo log 日志了,在事务执行的过程中,redo log 开始逐步落盘
- 当对应事务的脏页写入到磁盘之后,redo log 的使命就完成了,它所占用的空间也就可以被覆盖了。
- InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB。从头开始写,写到末尾就又回到开头循环写
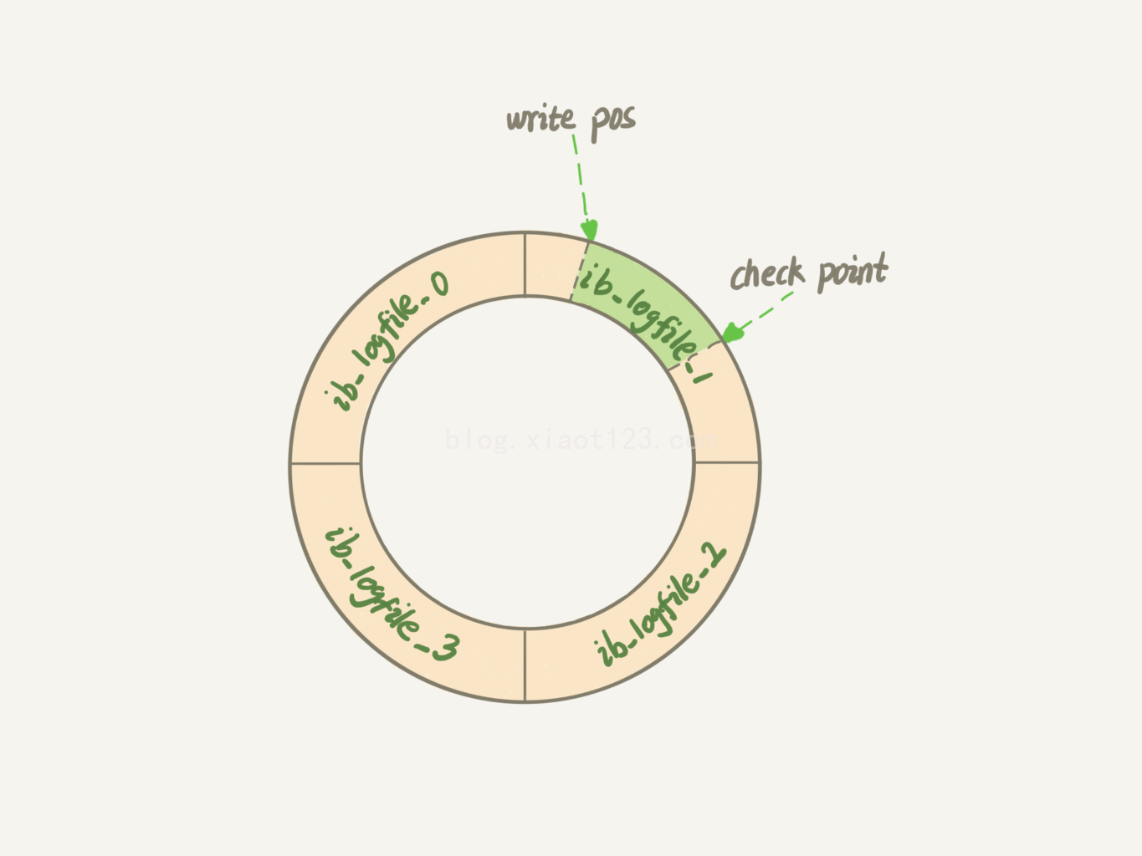
- write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
- write pos 和 checkpoint 之间的的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。
存储内容
redo log 包括两部分:
- 一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;
- 二是磁盘上的重做日志文件(redo log file),该部分日志是持久的,redo log 存储的是物理格式的日志,记录的是物理数据页面的修改信息,它是顺序写入 redo log file 中的。
落盘方式(将 innodb 日志缓冲区的日志刷新到磁盘)
- Master Thread 每秒一次执行刷新 Innodb_log_buffer 到重做日志文件
- 每个事务提交时会将重做日志刷新到重做日志文件
- 当重做日志缓存可用空间少于一半时,重做日志缓存被刷新到重做日志文件
注意:
- 其实写redo log的时候,也会有buffer,是先写buffer,再真正落到磁盘中的。至于从buffer什么时候落磁盘,会有配置供我们配置。
- redo log 是 InnoDB 引擎特有的日志
- 持久性就是靠redo log来实现的(如果写入内存成功,但数据还没真正刷到磁盘,如果此时的数据库挂了,我们可以靠redo log来恢复内存的数据,这就实现了持久性)。
undo log (回滚日志)
保存了事务发生之前的数据的一个版本,作用:
- 可以用于回滚
- 同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
生命周期
- 事务开始之前,将当前事务版本生成 undo log,undo log 也会产生 redo log 来保证 undo log 的可靠性。
- 当事务提交之后,undo log 并不能立马被删除,而是放入待清理的链表
- 由 purge 线程判断是否有其它事务在使用 undo 段中表的上一个事务之前的版本信息,从而决定是否可以清理 undo log 的日志空间。
存储内容
undo log 存储的是逻辑格式的日志,保存了事务发生之前的上一个版本的数据,可以用于回滚。当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着 undo 链找到满足其可见性的记录。
存储位置
默认情况下,undo 文件是保存在共享表空间的,也即 ibdatafile 文件中,当数据库中发生一些大的事务性操作的时候,要生成大量的 undo log 信息,这些信息全部保存在共享表空间中,因此共享表空间可能会变得很大,默认情况下,也就是 undo log 使用共享表空间的时候,被“撑大”的共享表空间是不会、也不能自动收缩的。因此,MySQL5.7 之后的“独立 undo 表空间”的配置就显得很有必要了。
binlog (二进制日志)
- binlog我们可以简单理解为:存储着每条变更的SQL语句
- 可以通过binlog来对数据进行恢复
- binlog 可以用于主从复制中,从库利用主库上的 binlog 进行重播,实现主从同步。用于数据库的基于时间点、位点等的还原操作。binlog 的模式分三种:Statement、Row、Mixed。
Statement模式
每一条修改数据的 sql 都会记录到 master 的 binlog 中,slave 在复制的时候,sql 进程会解析成和原来在 master 端执行时的相同的 sql 再执行。
- 优点:在 statement 模式下首先就是解决了 row 模式的缺点,不需要记录每一行数据的变化,从而减少了 binlog 的日志量,节省了 I/O 以及存储资源,提高性能。因为它只需要记录在 master 上执行的语句的细节以及执行语句的上下文信息。
- 缺点:在 statement 模式下,由于它是记录的执行语句,所以,为了让这些语句在 slave 端也能正确执行,那么它还必须记录每条语句在执行的时候的一些相关信息,即上下文信息,以保证所有语句在 slave 端和在 master 端执行结果相同。另外就是,由于 MySQL 现在发展比较快,很多新功能不断的加入,使 MySQL 的复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug 也就越容易出现。在statement 中,目前已经发现不少情况会造成 MySQL 的复制出现问题,主要是在修改数据的时候使用了某些特定的函数或者功能才会出现,比如:sleep() 函数在有些版本中就不能被正确复制,在存储过程中使用了 last_insert_id() 函数,可能会使 slave 和 master 上得到不一致的 id 等等。由于 row 模式是基于每一行来记录变化的,所以不会出现类似的问题。
Row 模式
日志中会记录每一行数据被修改的形式,然后在 slave 端再对相同的数据进行修改。row 模式只记录要修改的数据,只有 value,不会有 sql 多表关联的情况。
- 优点:在 row 模式下,binlog 中可以不记录执行的 sql 语句的上下文相关的信息,仅仅只需要记录哪一条记录被修改了,修改成什么样了,所以 row 的日志内容会非常清楚的记录下每一行数据的修改细节,非常容易理解。而且不会出现某些特定情况下的存储过程和 function,以及 trigger 的调用和触发无法被正确复制问题。
- 缺点:在 row 模式下,当所有执行语句记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
Mixed 模式
从官方文档中看到,之前的 MySQL 一直都只有基于 statement 的复制模式,直到 5.1.5 版本的 MySQL 才开始支持 row 复制。从 5.0 开始,MySQL 的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给 MySQL Replication 又带来了更大的新挑战。另外,看到官方文档说,从 5.1.8 版本开始,MySQL 提供了除 Statement 和 Row 之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。在 Mixed 模式下,MySQL 会根据执行的每一条具体的 SQL 语句来区分对待记录的日志形式,也就是在 statement 和 row 之间选择一种。新版本中的 statment 还是和以前一样,仅仅记录执行的语句。而新版本的 MySQL 也对 row 模式做了优化,并不是所有的修改都会以 row 模式来记录,比如遇到表结构变更的时候就会以 statement 模式来记录,如果 SQL 语句确实就是 update 或者 delete 等修改数据的语句,那么还是会记录所有行的变更。
生命周期
事务提交的时候,一次性将事务中的 sql 语句(一个事务可能对应多个 sql 语句)按照一定的格式记录到 binlog 中,这里与 redo log 很明显的差异就是 redo log 并不一定是在事务提交的时候才刷新到磁盘,而是在事务开始之后就开始逐步写入磁盘。binlog 的默认保存时间是由参数 expire_logs_days 配置的,对于非活动的日志文件,在生成时间超过 expire_logs_days 配置的天数之后,会被自动删除。
binlog和redo log 写入的细节 - 两阶段提交
MySQL通过两阶段提交来保证redo log和binlog的数据是一致的
update T set c=c+1 where ID=2;这里我给出这个 update 语句的执行流程图,图中浅色框表示是在 InnoDB 内部执行的,深色框表示是在执行器中执行的
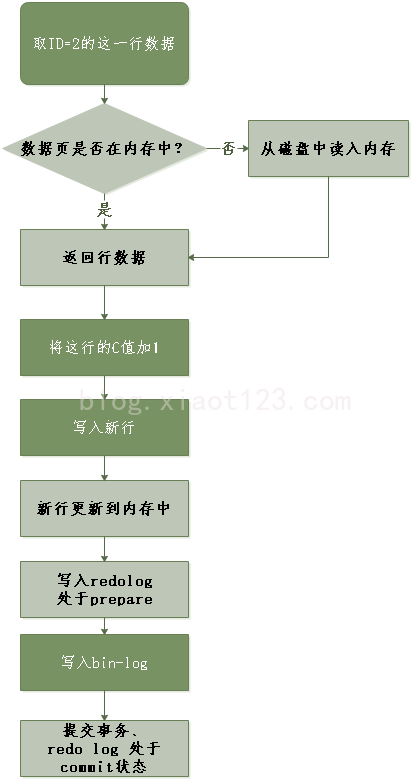
将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是”两阶段提交”。
原文链接:

